
In most clinical operations today, only 50–60% of medical terms are automatically coded. The rest? Manual review. Multiple passes. Hours of coder time per study. This bottleneck drags down data quality and delays critical downstream analysis.
Medical coding sits at the center of clinical trial operations, yet the process has remained largely unchanged for years. It’s time for a fundamental shift.
Today’s workflows still rely on rules-based auto-coding tools supported by multiple layers of human review. While foundational, these systems struggle to keep pace with the complexity and volume of modern clinical data. Synonym lists can enhance coverage, but building and maintaining them is a significant operational challenge. The result is a process that’s too manual, too repetitive, and too slow for the demands of today’s clinical trials.
The Current Medical Coding Process
In most organizations, medical coding follows a familiar workflow:
- A rules-based auto-coding tool attempts to classify terms.
- Coders manually review the output, often in two separate review stages.
- Teams maintain synonym libraries to boost automated coverage, which is an ongoing and resource-heavy task.
This workflow has remained largely unchanged for years. And while it functions, it leaves significant opportunities for improvement in both accuracy and efficiency. Bottlenecks form when auto-coding falls short, dictionary updates remain time-consuming, and manual review effort scales linearly with study size.
To solve these long-standing challenges, we need approaches that can understand language, handle ambiguity, and scale effortlessly with growing data. This is where modern Natural Language Processing (NLP) techniques come in.
Natural Language Processing (NLP) Techniques in Medical Coding
NLP techniques generally fall into three major categories, each offering different levels of complexity, flexibility, and performance:
- Symbolic methods: rule-based parsing or approximate string matching
- Machine Learning (ML): models such as support vector machines or logistic regression
- Deep Learning (DL): architectures like recurrent neural networks or Large Language Models (LLMs)
Selecting the right NLP approach requires understanding the specific challenges of the use case. In medical coding, these challenges include highly specialized vocabulary, frequent introduction of new or ambiguous terms, and a vast number of potential dictionary outputs.
Although DL is technically a subset of ML, the two operate quite differently. Traditional ML models generally rely on more extensive data preparation and engineered features. DL models require less manual feature engineering but are built on more complex architectures, meaning they typically need larger training datasets to perform effectively.
Machine Learning (ML) for Medical Coding
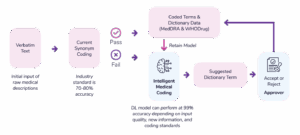
ML can streamline today’s medical coding workflow by acting as a first-line reviewer and eliminating the need for extensive synonym lists. In this approach, a simplified rules-based auto-coding tool handles the more straightforward terms. Any remaining verbatim terms are then passed to an ML model, which identifies the most likely dictionary match. A second-line medical coder reviews the model’s suggestion and confirms the final code.
For ML to perform effectively, the model must read both the input term and the dictionary entries, interpret their meaning, and retrieve the most appropriate match. This reliance on language understanding underscores why NLP techniques are well-suited for medical coding and why ML can offer meaningful efficiency gains.
Deep Learning (DL) for Medical Coding
DL can go even further in addressing the inherent complexity of medical coding. DL models are flexible enough to learn relationships across words and phrases within an input term, enabling them to interpret meaning without relying on rigid assumptions or organization-specific rules.
By leveraging semantics, DL models can accurately select the correct dictionary entry from many possible options—even when input terms are highly variable or phrased in unexpected ways. Techniques like transfer learning also enable DL models to incorporate prior medical knowledge, thereby improving performance and allowing them to handle terms that were never seen during training.
For example:
- The input “probable COVID-19 infection” is correctly coded as “suspected COVID-19” because the model recognizes “probable” and “suspected” as contextually similar and focuses on “COVID-19” as the primary concept.
- The term “honeydew melon allergy” is coded as “fruit allergy,” even though the dictionary has no more specific entry; the model utilizes prior knowledge that honeydew melon is a type of fruit.
Instead of returning a single prediction, DL models can also provide multiple suggested codes with a confidence score, helping coders quickly identify low-confidence cases that require closer review.
Using a DL-based solution, we have typically achieved greater than 90% accuracy in both adverse event and medication coding. These results clearly demonstrate that DL is highly effective for medical coding.
CluePoints’ Intelligent Medical Coding (IMC)
DL’s ability to understand context, interpret medical language, and generalize beyond pre-defined rules creates a powerful opportunity to rethink medical coding entirely. This is precisely why we built Intelligent Medical Coding (IMC): a DL-driven solution purpose-built to overcome the inefficiencies and limitations of conventional coding workflows.
IMC dramatically improves coding accuracy, reduces manual workload, and streamlines operations across studies. Instead of relying on synonym lists or extensive human intervention, IMC applies advanced DL models trained on coded terms and dictionary data (MedDRA and WHODrug), continually refining its understanding as more data is processed.
Key benefits:
- Higher accuracy: Consistently exceeds 90% coding accuracy for adverse events and medications
- Reduced manual effort: Eliminates the need to build and maintain extensive synonym libraries
- Faster throughput: Accelerates coding timelines by automating first-line review with confidence scoring
- Scalability: Performance improves with data volume rather than degrading under load
Medical coding no longer needs to be a bottleneck. With IMC, organizations can transform their coding operations from a manual, resource-intensive process into a streamlined, intelligent system that scales with the demands of modern clinical trials.
The Future of DL & ML in Medical Coding
Two promising areas of continued innovation in medical coding are automated query detection and the direct coding of high-confidence terms.
ML can reduce quality-control effort by not only identifying the most likely dictionary match but also proactively raising queries when input terms deviate from expected patterns. CluePoints is already advancing this space through Intelligent Query Detection (IQD), which uses DL to detect discrepancies and streamline the query-raising process.
At the same time, high-confidence predictions open the door to direct coding, where terms above a defined confidence threshold can be bypassed entirely through manual review. This represents the next major opportunity to reduce workload and accelerate timelines.
Together, these advancements, along with the efficiencies already demonstrated, make a strong case for expanding the role of ML and DL within medical coding.
Ready to upgrade your coding workflows? Explore how IMC is transforming medical coding.
